

In the current SDI-centric world where specialised cabling is used to carry media signals, studio infrastructure is defined fairly statically, using physical connections, manual configuration, and specialised routing. In an IP-based approach such as our IP Studio project, these connections, routes and devices may be virtual. This presents a problem: how do we know what is available, where it is available, and most importantly, how to get to it? This is a timely question, with discussion ongoing in the wider industry as to how this can be managed effectively and flexibly.
Of course, static manual configuration is still an option. However, in our experience, managing static configuration can be difficult, especially when virtual devices might appear from nowhere (such as a "pop-up" production at an event) or only exist for a short time. We think that the flexibility of an all-IP approach can (and should) do better, allowing more dynamic environments. A guiding principle for our work is minimal (or non-existent) configuration: it should be possible to plug an IP-based video camera in, and immediately have the pictures it produces available on the network. Based upon the model developed by the (JT-NM) and published as a key part of the , we have implemented a "discovery and registration" system which allows networked media devices and resources to be automatically recognised and made available. This brings benefits in terms of agility, independence from physical location, and a reduction in configuration time.
Resource Representation
A core part of the IP Studio project is the data model which describes how resources (cameras, displays, media feeds, etc.) are represented within the system. Central to this is the concept of identity: every鈥卹esource鈥卆s鈥厀ell鈥卆s鈥卐very鈥卻tream鈥卭f鈥卾ideo,鈥卆udio,鈥卭r鈥卍ata鈥協lowing鈥卼hrough鈥卼he鈥卻ystem is given a unique identifier.
A fundamental unit of the model is the Device, something which can provide services or resources (such as audio and video) on the network. This may be a fixed-function hardware device, a software-based virtual device running on a generic compute platform (a 'Node'), or anything in between. A REST API is presented by each Node, which describes the resources and services it provides. The problem is how to enumerate and connect these resources so that other applications and devices on the network can "see" what is available in a way that is consistent, flexible, reasonably efficient, and amenable to expansion. This is what "discovery and registration" seeks to address.
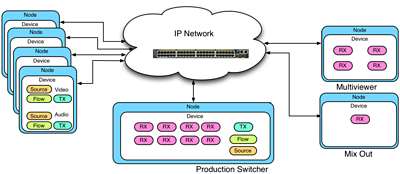
Data model as it might appear in a small IP Studio set-up. Resources are provided by Nodes and Devices.
Our current approach separates responsibilities into three areas:
- A registration interface, used to add, update, and delete resources;
- A query interface, used by clients to obtain information about available resources;
- A registry component, for data storage and distribution.
This is implemented as two very simple services, each presenting a REST API, and a data store with which those services communicate internally. Separating registration and query means each component is doing a well-defined job, and also allows flexibility when it comes to deployment. For example, more query instances could be added in a busy environment, or the registration service could be deployed with different access constraints to the query interface. These APIs together form the interface to the IP Studio registry - as long as a Device implementation conforms to the relevant part of the service API, the resources it provides will be visible to IP Studio. We chose to use JSON over HTTP for both interfaces as it is well understood, well supported by a host of modern tools, easily inspected, and familiar to a large base of developers. In addition, this allows us to draw on the robustness of the protocol, as well as well-defined semantics for things like alternative representation and failure modes. Modelling resources available on the network in this way separates the resource model and the advertisement of services, and allows us to represent the data model directly.
Our previous prototype used (best known through Apple's "Bonjour" implementation) to represent all available resources on the network, each as a separately maintained advertisement. Scaling this approach presented several issues: the number of 'live' advertisements grows rapidly, the information stored with each advertisement is limited (which leads to clients communicating individually with nodes en-masse), and the distribution of advertisements across multiple networks is fiddly. In our , we found that these issues added up quickly and led to some instability across a large installation. Taking a different approach has allowed us to address these issues and also improve various non-functional aspects of the system.
The registration and query interfaces are advertised locally using mDNS/DNS-SD. This allows any new device on the network to "discover" a local registration service (which may be one of many) and register resources. New clients can find a local query service to obtain a complete view of the system. The query interface can be used as an HTTP-based API, and also has the capability to provide "watches" of resources (via WebSockets) to allow clients to react more dynamically to changes. Separating the concerns of discovering the core API services from the representation and storage of the domain-level resources reduces the pressure on mDNS/DNS-SD, whilst retaining the automatic, zero-configuration aspect. It also allows the resource interface to be richer and more flexible, allowing us to experiment with representation and data layout. As a consequence, the data model exposed by the query interface matches the logical domain model closely. Devices need know nothing about the registry component, allowing freedom to choose an appropriate data store for a particular implementation.
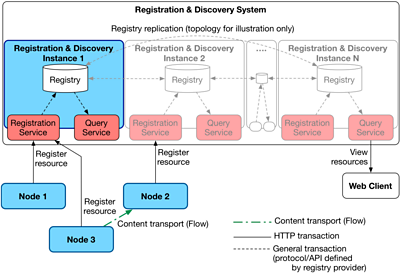
Overview of one possible arrangement of the discovery and registration components.
In our implementation we are using a distributed key/value store with good consistency guarantees for the registry component (an open-source implementation based on the algorithm), which means that data present in one instance is present in all. We use this property to provide a system-wide view of the data by having an instance of the store available in each subnet (we actually use a cluster of 5 stores, to provide fault-tolerance). Information is propagated to all stores, so that the resources seen by each query interface are identical. The architecture is designed to allow different data store choices, so that the trade-offs can be balanced according to requirements. It is the registration and query interfaces that are key to that flexibility, as a conforming device need only concern itself with interaction with those components. Although not described here, this approach can also scale down for point-to-point use cases which require a low number of devices, such as a single camera and monitor, without requiring the overhead of a full registry.
A real-world system will need to cope with the unexpected, such as power interruption or loss of connectivity. We use a simple "heartbeat" approach to deal with such cases, which has been more than adequate for our trials.
The IP Studio data model exposed by the query interface has been used to build several web-based management and control tools with rich user interfaces. We wanted these to be "zero configuration" too, so by necessity each interface must "find" a query service to talk to. However, not all web browsers have support for mDNS/DNS-SD, so we needed a way of bridging this gap. We implemented a small, lightweight service which we imaginatively dubbed the mDNS Bridge. This maintains a list of mDNS advertised services and makes them available over HTTP, again as JSON, allowing systems with no knowledge of mDNS/DNS-SD to easily access the discovery system. Any server running IP Studio web applications can make use of this to allow other IP Studio services to be discovered by the client, removing the need for complex configuration.
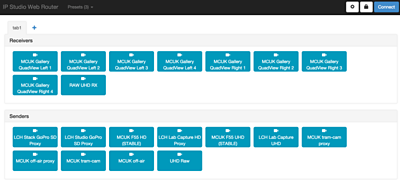
Example web-based user interface for IP Studio, using data from registration system.
This approach, along with our reference implementations, have recently played a large role in an to practically evaluate this way of doing things, with great success. This forms part of the 's (AMWA) Networked Media Incubator project, which seeks to bring industry partners together in order to implement and test interoperability. The work done within the Networked Media Incubator project is now a draft AMWA Networked Media Open Specification, available on , and details the APIs discussed above (and more).
For more information on any of the above, please contact the IP Studio team.
- Sign up for the IP Studio Insider Newsletter:
- Join our mailing list and receive news and updates from our IP Studio team every quarter. Privacy Notice
- First Name:
- Last Name:
- Company:
- Email:
- or Unsubscribe
- -
- 大象传媒 R&D - High Speed Networking: Open Sourcing our Kernel Bypass Work
- 大象传媒 R&D - Beyond Streams and Files - Storing Frames in the Cloud
- 大象传媒 R&D - IP Studio
- 大象传媒 R&D - IP Studio: Lightweight Live
- 大象传媒 R&D - IP Studio: 2017 in Review - 2016 in Review
- 大象传媒 R&D - IP Studio Update: Partners and Video Production in the Cloud
- 大象传媒 R&D - Running an IP Studio
- 大象传媒 R&D - Building a Live Television Video Mixing Application for the Browser
- 大象传媒 R&D - Nearly Live Production
- 大象传媒 R&D - Discovery and Registration in IP Studio
- 大象传媒 R&D - Media Synchronisation in the IP Studio
- 大象传媒 R&D - Industry Workshop on Professional Networked Media
- 大象传媒 R&D - The IP Studio
- 大象传媒 R&D - IP Studio at the UK Network Operators Forum
- 大象传媒 R&D - Industry Workshop on Professional Networked Media
- 大象传媒 R&D - Covering the Glasgow 2014 Commonwealth Games using IP Studio
- 大象传媒 R&D - Investigating the IP future for 大象传媒 Northern Ireland
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section