

In the first and second posts in this series our colleague Sam talked about tests we ran to measure the raw performance of S3 as a storage medium for uncompressed video frames. Based on what we learnt from that work the idea of using S3 as a storage back-end for uncompressed video seemed reasonable, but we were still quite some way from having an implemented storage system that would work as a proof-of-concept for this idea. So we designed and built one.

A Store Named Squirrel
We’ve called our experimental media store "Squirrel": it seemed a good fit with our principle of storing small objects in a distributed manner!
The Squirrel store is, at its heart, a fairly simple architecture. To build it, we’ve continued to prototype on Amazon Web Services, using AWS S3 for object storage, but the general principles are highly portable:
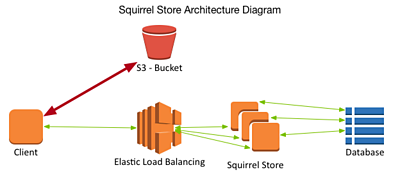
Squirrel’s S3 bucket stores small units of media as objects, and an "index" is written to a distributed NoSQL database (DynamoDB in this case). This index database allows Squirrel to define relationships between individual objects – for example describing how they can be ordered in time to make a continuous piece of media.
We also designed a simple API to hide some of the database implementation from clients of Squirrel.
From our earlier work, we observed that 10MB objects, moved in parallel, were a good balance between latency, cost and speed. Conveniently, uncompressed HD video frames are around this size in the form we are storing them (). Therefore, we made each S3 object a single frame of video, and each database entry describes that frame's identity and timing (for which we used the existing Grain, Source and Flow identifiers introduced as part of the broadcast industry’s activity).
Writing and reading data to and from Squirrel then starts to look like this:
Writing to the Store
- Write a set of Flow metadata to the database using the Squirrel API
- For each Grain in the Flow (eg. a frame of uncompressed video in our example):
- Upload the Grain data to a new object in the S3 bucket.
- Write an entry for the Grain to the database using the Squirrel API. This associates the object in the bucket with a particular time stamp within the already created Flow
Reading from the Store
- Read a set of Flow metadata from the database using the Squirrel Store API.
- For each timestamp where a frame is expected in the Flow:
- Read the entry from the database which corresponds to that timestamp and extract the object key.
- Use the object key to download the frame data from the bucket.
How to Structure a Client
The next step in our prototyping process was to consider how Squirrel would interact with clients reading and writing real media. We developed a few simple designs to explore likely scenarios, which are described below.
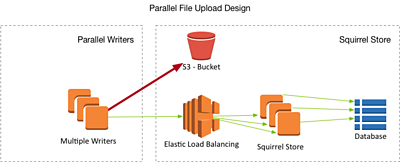
File Uploads: Data is available when you want it
In this scenario, an original file is first uploaded as a whole to an external S3 bucket (e.g. external-input.rawvideo, a file which originates from outside our cloud-domain). Then a number of writer instances are spun up, which each pull frames from the file and ingest them into Squirrel until the whole file has been turned into small objects.
This approach is extremely scalable and takes advantage of the natural parallelisability of cloud computing platforms. In principle the rate at which the ingest can run once the initial file has been uploaded is constrained only by the number of writer instances that are spun up. This approach also has a great deal of advantage in terms of cost, as it allows the work to be shared between multiple smaller instances: we know from our earlier tests that performance will scale linearly.
Stream Reception: Things arrive when they do
In this scenario, a single input stream of external origin (e.g. an RTP stream) needs to be ingested into the Squirrel media store from outside of our cloud domain.
If video data is arriving in a stream (which is a pretty common thing to happen in a production environment) then the data arrives when it arrives (i.e. we cannot look ahead into the future of the stream), so the architecture of the writers looks a little different:
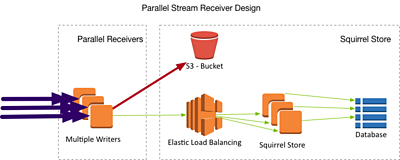
We still have a scalable group of writer instances, but now each of them is receiving the full stream of incoming data. We can manage the fan-out of traffic from the input stream entirely within our writer components, so as not to place additional load on the stream origin server.
Each of these writers is configured to ignore frames which will be handled by another writer. This way the whole of the stream will be uploaded, but the work is shared out amongst the workers. A simple message queue can be used to coordinate the writers so that no two take the same frame.
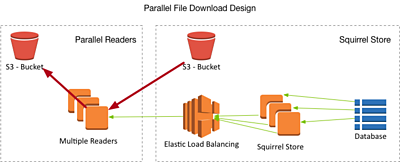
Parallel File Download
Here, several small media objects that already exist in the Squirrel media store need to be combined into one longer file. This file is then made available for download by an external client (e.g. as output-file.rawvideo) outside of our cloud domain.
Similar to an upload, a download can be performed quickly in a parallel fashion because all of the data is already available in Squirrel:
Parallel Stream Creation
In this case, several small media objects that already exist in the Squirrel media store need to be combined into a single stream for onward transmission: the stream will be delivered to an external client outside of our cloud domain (e.g. as an output RTP stream).
Originating a stream (which is also often a thing needed in production environments) is probably the hardest option we considered. Doing it in parallel requires the coordination of packets from different sources to make the same stream, which is achievable using UDP, but for TCP-based streaming protocols it's likely that the file-based approach above is more practical. Still, when we can do it, the stream transmitter is theoretically extremely low latency:
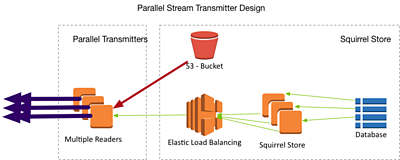
Parallel Renderer
Whilst reading things out of the store and writing them in is very important, many of our more interesting plans for on-the-fly video processing involve reading data from the store, processing it in some way, and then writing the modified data back.
This is something that would typically take place when rendering media as part of a production. In principle a client that does this has the following layout:
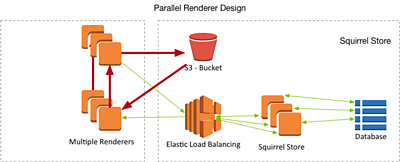
Tests We Ran, and What they Showed
With the above designs in mind, we created a set of simple proof-of-concept tests which emulate the parallel stream reception and stream creation designs above.
For all of our testing, we used real uncompressed HD video frames, though not particularly interesting ones ("luma steps" is probably the most uninteresting test signal we can generate, but it's easy to work with and we can generate it simply using the built in test signal generator in our open source ).
The test code wrote these frames into the Squirrel store at a variety of frame rates with a variety of different sizes of instance, and we recorded which frame-rates worked for which instance sizes. Then we did the same for reading, and then also for the combined operation of reading from a store and writing back to it.
Since the size of instance used is a key factor in the price we're charged by the cloud provider, we were able to model the lowest price available at each frame-rate when using a single instance of variable size, or when using multiple instances of constant size. The results were good enough to show us that our approach to storing frames in Squirrel is viable from both a technical and cost perspective (even with a simple, un-optimised implementation).
So What Comes Next?
In the near future we're going to be starting the next phase of this project in which we'll be building on our proof-of-concept Squirrel store implementation to increase its resilience, and to add additional services which allow real media files to be uploaded to the store and downloaded from it.
As part of this work, we'll be writing about our approach to storing other media formats in Squirrel, such as compressed video.
Beyond that we have a number of other projects in mind for it which will add the ability to dynamically render and transcode media objects on-the-fly as they are needed, something which this kind of cloud platform should excel at.
-

Automated Production and Media Management section
This project is part of the Automated Production and Media Management section