

Machine learning (ML) methods have recently become a source of innovation in many research fields and have brought substantial advancements when applied to visual data. 大象传媒 Research & Development's Visual Data Analytics (VDA) team examines these ML algorithms and develops novel methods that can help improve the 大象传媒's content production and distribution workflows.
Through a recent research collaboration with the , the VDA team has been exploring how machine learning can automatically summarise video content and help producers and editors operate more efficiently. Consequently, we have developed a system that can create a package of frames summarising the contents of a video based on what subjects and interests the user specifies.

Video summarisation
Video data is increasingly important, especially in journalism, where editing captured raw video footage and selecting relevant segments is a fundamental but mundane task. To help make it quicker to access the important parts of video footage, the research community has developed ways to automatically summarise what is in the video using ML. The trained algorithm automatically generates a fixed video summary that can identify and include key segments and leave out shots that do not add to the story. Although the conventional methods select essential video information, they are not personalised for a user's specific needs, limiting their effectiveness and how they could be used.
Query-based video summarisation
Additional options can be added to the summarisation process. Different contextual data, from video captions to viewers' comments, can be used to generate more useful and more specific summaries for each video. For example, the user can control the summarisation algorithm by entering a text-based query. The query steers the method to produce a summary that accurately represents the needs of the user.
Query-dependent video summarisation can capture and tailor information that is relevant to producers' and editors' specific requirements, giving them much greater flexibility. In the example of a sports video shown below (indicated as Video Input), a producer might want a video summary of swimming clips (Input query-1) or of running (Input query-2). By entering the text queries as inputs to the developed ML system, they enable the input video to be summarised in two distinct ways, generating Query-dependent summary-1 and Query-dependent summary-2.
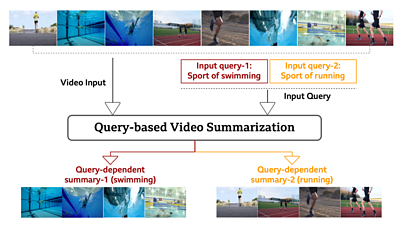
Our approach
At 大象传媒 R&D, we have developed an ML system that efficiently captures the implicit interactions between the query and the video to produce a query-based video summary. This is achieved with the help of an attention mechanism, a method that imitates human attention by identifying the relevant context in the data and putting more emphasis on it.
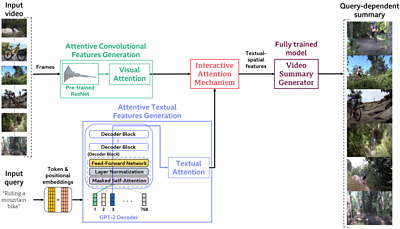
The input video is first sampled on a frame level, and a pre-trained Convolutional Neural Network (CNN), based on the well-known architecture, is used to extract spatial features from the selected frames before a visual attention method is applied. Significant words and phrases are identified from the user's input query by applying textual attention on a neural network architecture inspired by the state-of-the-art .
The attentive textual and visual features from the user's search query and the video are combined in a novel interactive attention mechanism. Finally, the combined elements are put into a fully trained model that generates the video summary.
The model was trained to work on videos of up to 3 minutes in length, with up to 8-word queries. An overview of the complete end-to-end query-based video summarisation system is displayed below.
You can read more about this work in the research paper , to be presented at .
What's next?
This video summarisation system currently performs well for a specific set of inputs and is ready for testing in existing video production workflows. Several improvements to the system are being finalised, most importantly a shot-based video processing. In this way, a summary package of clips, rather than frames, can be generated.
However, to develop a robust and reliable system, the method would also have to evaluate and accommodate the audio within the video footage - as it does not at present. More post-processing methods could also be added to allow for smoother transitions between scenes.
This work was carried out within the in collaboration with Jia-Hong Huang and Marcel Worring from the of the , and with the and the .
- -
- 大象传媒 R&D - Video Coding
- 大象传媒 R&D - COGNITUS
- 大象传媒 R&D - Faster Video Compression Using Machine Learning
- 大象传媒 R&D - AI & Auto Colourisation - Black & White to Colour with Machine Learning
- 大象传媒 R&D - Capturing User Generated Content on 大象传媒 Music Day with COGNITUS
- 大象传媒 R&D - Testing AV1 and VVC
- 大象传媒 R&D - Turing codec: open-source HEVC video compression
- 大象传媒 R&D - Comparing MPEG and AOMedia
- 大象传媒 R&D - Joining the Alliance for Open Media
