
The ability to capture videos on mobile phones has introduced a potentially unlimited number of 'on the scene' views to news editors covering events. These types of video often capture the most unique, relevant and authentic moments, which are essential for a good story.
Content generated by those attending an event brings an immediacy and enriched coverage but can also flood editors with a constant stream of information that needs to be curated. Editors need to judge the newsworthiness of the material to choose what video clips should be selected for use alongside other footage to create an engaging and coherent story.
This skilful task requires manual searches of massive amounts of data, which takes a great deal of time and resources. 大象传媒 Research & Development is collaborating with the to automate this process and NOVA's Joao Magalhaes explains below how we are developing content-filtering tools to make searching quick and effective while editors maintain complete control of the final result.

When illustrating a news story, the goal is to create an informative, cohesive and appealing visual sequence that best conveys the timeline of events. The package is structured into story segments that describe parts of the event. Many things influence why producers and editors use different pieces of content to represent specific segments. Our research aims to derive a computational framework for visual storyline illustration that closely follows the principles and criteria employed by editors in the newsroom.
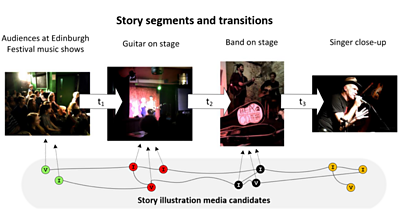
This work continues our previous collaboration with NOVA which introduced a benchmark for automated news storytelling. Our challenge now is to automate the editorial process to assist news editors.
To do this, we need to firstly, find the right video footage from all the available sources, and secondly, understand the timeline of events that feature in the news story.
Our Approach
Our system to automate the selection of images or video clips for a story or news report consists of 3 steps:
- The editor enters a story topic and its story segments as a text query.
- The framework selects images or videos that illustrate the story segments.
- This compilation is then presented to the editor for selection and post-editing.
Instead of struggling to decide from one of the many different ways to illustrate the story, the editor can iteratively browse different sequences created from the footage and work from there.
We designed a graph-based framework to semi-automate a selection of footage so that the visual storyline is succinct, cohesive and the sequence has an interesting and relevant narrative.
The first part of this process focuses on story transitions from one story segment to another. Deciding how the transitions happen is a challenge because it will ultimately affect the visual quality of the story, as judged by a human. Therefore, to organise the story segments and define the transitions, our approach predicts the perceived transition quality of neighbouring segments by analysing their visual and semantic characteristics.
We do this by formally defining the transition between two images based on a distance ensemble of multimodal visual features (e.g. colour, luminance, objects, etc.). We then use this definition to automatically assess the transition between many sets of images, evaluating the quality by analysing their visual and semantic characteristics.
Machine learning tools create the transition between two images; in particular, transition points are decided using an ensemble of regression trees over a set of distances between multimodal features in the footage we provided. We trained a gradient boosted regressor to learn which elements maximise the quality of transitions, with ground truth obtained by human annotators.
The proposed framework tackles the second important task: moving beyond the transitions between separate segments in one packaged report to select specific footage to represent that segment. To do this, it uses another machine learning technique known as multimodal graph-based methods to look at the storyline as a whole and produce a visual storyline, as shown in the image above, by finding a set of candidate multimodal sources to illustrate each segment.
Two fundamentally different structures are considered: a bipartite graph and a multipartite graph. We optimise the bipartite graph to create visual storylines with the best possible sequential transitions while considering the relevance of the content. The visual storyline is obtained by finding the shortest path in the graph, where the distance between elements of neighbouring segments is defined by the predicted transition quality and relevance of the content.
On the other hand, the multipartite graph assesses transitions between all elements (the footage) available for the story, optimising for maximal cohesion. This process leverages the possibility that individual transition quality is affected by the remaining elements of the storyline.
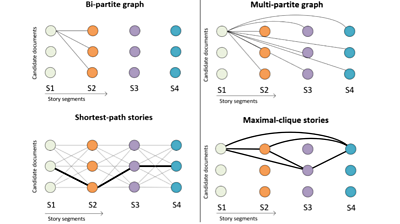
This graph-based formulation is capable of representing visual storylines taking into account numerous images and videos. It provides the necessary flexibility to adapt to different settings (e.g. arbitrary number of story segments). Most importantly, it results in a computationally efficient solution that can quickly generate alternative visual storylines so that it can be used interactively.
What were the key takeaways?
We carried out user testing, gaining new insights into what impacts the perception of news storyline illustrations. We conclude that a storyline is perceived best when targeting maximum cohesion among all story illustrations (using our multipartite graph). Additionally, our study shows that maximum cohesion also leads to a better sense of the relevance of the news story illustration.
When analysing the performance of our framework at the point of transition quality evaluation, we observed that the most determinant visual characteristic responsible for achieving higher transition quality is semantic similarity. Our experiments show that storylines with the best quality avoid abrupt semantic shifts, which can be done by placing images and footage that show similar things close together.
The colour difference between sequential images in a storyline should be minimised to make the news package appealing; this supports our assumption that using content with similar colour palettes is a solid way to optimise the quality of visual storylines.
The result of our work is a framework that can highlight some of the methodological patterns editors use when illustrating storylines, despite the subjective nature of the task. It is possible to systematically and accurately predict the quality of transitions in an automated way, leaving the editor to make any final adjustments.
- You can read more about this work in our paper: Gon莽alo Marcelino, David Semedo, Andre Mourao, Saverio Blasi, Joao Magalhaes and Marta Mrak, "Assisting News Media Editors with Cohesive Visual Storylines", in Proc. ACM Multimedia 2021. [] [].
- This work was carried out as part of the H2020 COGNITUS project, in collaboration with the from .
- -
- 大象传媒 R&D - Helping to automate storytelling for news events
- 大象传媒 R&D - COGNITUS
- 大象传媒 R&D - Capturing User Generated Content on 大象传媒 Music Day with COGNITUS
- 大象传媒 R&D - COGNITUS at the Edinburgh Festival 2017
- 大象传媒 R&D - AI Opportunities: Transforming Coverage of Live Events
- 大象传媒 R&D - AI & Auto colourisation: Chasing rainbows with transformers