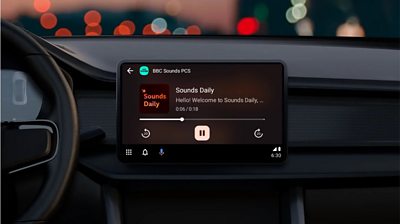

The development of technology within connected cars continues to transform the driving experience, making it more engaging and interactive. Drivers increasingly use the morning commute to stream content like music and podcasts and this shift in behaviour is an opportunity to enhance a user's commute by personalising it. The Sounds Lab team has been experimenting with improving this commute by delivering a stream of short-form content based on a user's listening habits and preferences in the ����ý Sounds mobile app.
Building on ����ý Research & Development’s work on in-car entertainment from 2016, we were able to test some of those findings with 80 participants in a live trial. This allowed us to delve deeper, exploring the use of synthetic media to enhance the user experience and gather insights into how audiences use and interact with Sounds Daily, its functionality, and potential areas for improvement.
We developed a service that generates a sequence by combining synthetic media and content from the ����ý Sounds catalogue. At the heart of the service is an function, which we refer to as the engine. Sequences are created by the engine communicating ����ý services, retrieving metadata and then requesting the generation of synthetic media.
Sequence generation starts with the engine requesting the sequence structure from StoryFormer, our tool designed to create flexible, responsive content. A sequence's defined structure can include various node types, such as Greetings (message acknowledging the listener), Signposts (trailing what is coming up on the stream) Interstitials (a bridge linking one piece of content to another) and Content (podcasts, music and other audio clips appearing in the stream) and the mix of these contributes to the flow of the sequence.
The engine parses the structure and generates the synthetic media for the non-content type nodes. Synthetic media is one of two types: static or dynamic. The ����ý Sounds editorial team creates static media utterances, such as greetings and onboarding messages, and GPT-4 generates the dynamic synthetic media utterances. For this, we use a prompt template. An example of such a prompt is an interstitial that links a piece of content. The variables within the prompt are dynamically populated with suggested content items provided by our recommender system.
Example: Prompt TemplateYou are a host introducing audio programmes on Sounds Daily. This is a trail. This is not the beginning of the stream. Present the following <ITEM>, followed by <ITEM> and <ITEM>. Use neutral or positive language. The message should be 15 seconds long. Include the programme titles, brand description and any presenters known. Do not characterise the stream as a radio station. |
Example: PromptYou are a host introducing audio programmes on Sounds Daily. This is a trail. This is not the beginning of the stream. Present the following Match of the Day Africa: Top 10 - Who is the best African Premier League player?, followed by The Friday Sports Panel - Friday Sports Panel and 6 Music Artist Collection - Christine and the Queens - Christine and the Queens Live. Use neutral or positive language. The message should be 15 seconds long. Include the programme titles, brand description and any presenters known. Do not characterise the stream as a radio station. |
Example: Response"Welcome back to Sounds Daily. We have some fantastic programmes lined up for you today! Coming up next is Match of the Day Africa: Top 10, where we reveal who the best African Premier League player is. After that, tune in to The Friday Sports Panel for some lively sporting discussion. And later, we have the 6 Music Artist Collection featuring Christine and the Queens Live. So, stay tuned for some top-quality content." |
Once the prompt is ready, it's sent to our deployment. The response generated by GPT-4 is then converted into an mp3 file using Azure AI Speech TTS service, ready for playback within the app.

For the content nodes, the engine retrieves suggested content from the ����ý Sounds recommendation system or ����ý Sounds’ search API. The blend of synthetic media and curated content results in a varied, lively and enjoyable listening experience!
This process produces a JSON file containing the playable items, which the Android Sounds Client then uses for playback. Much of the interfacing between the Android Sounds Client and Sounds backend was made easier using R&D's Sounds Sandbox, which allows for experimentation in an environment close to the live one.
During testing, we encountered several issues with the quality of the generated output. We had content order inconsistencies disrupting the narrative, and some interstitials would refer to what had just played instead of what was coming next. The most notable thing we experienced was content confusion, where the podcast 28ish Days Later was identified as the film .
Potential solutions to address the issues with the prompt responses include:
- error-checking the response with code to validate the correct order,
- refining the prompts with more explicit instructions on content emphasis and order,
- providing existing data to reduce knowledge gaps (RAG)
- explore generating prompts using a Large Language Model (LLM) of our own and have greater control over the content.
Another challenge was delivering fresh content to a user. For example, a stream generated at 06:00 containing national news could become outdated in a few hours because of the frequent nature of news updates. To address this issue, nodes with the genre local_news, news, sport and football were treated as placeholders. When retrieving a generated stream, they are re-fetched to ensure the latest version of content is served.
What's next?
Looking ahead, our focus will be on adding support for and enhancing the mobile client's stream state management. We plan to enhance this by implementing a feature that informs the engine when a stream is nearing the end, ensuring a seamless experience between newly generated streams. Furthermore, we aim to improve our editorial tools by integrating elements of StoryFormer with our existing work on in-car entertainment, making the workflow more efficient for editorial teams.
-
What is Sounds Daily?
Our trial of in-car, personalised short & long form audio based on listening history. -

Beyond recommendations
More than just personalisation - AI generated synthetic voices greet drivers and introduce programmes. -

Building our trial
Creating the recommendations and generating the synthetic voices with prompt templates. -

Feedback and conclusions
Audience feedback has been important, helping us shape the trial.